|
I am a Ph.D. student in Paul G. Allen School of Computer Science & Engineering, University of Washington, advised by Ranjay Krishna. I am affiliated with the UW Graphics and Imaging Laboratory (GRAIL). I received my master degree from the Department of Computer Science, UCLA, where I was a research assistant under the supervision of Prof. Cho-jui Hsieh. I also collaborated with Prof. Xiaolong Wang at UCSD. I obtained my BEng. degree from the Department of Electronic Engineering, Tsinghua University, and I worked with Prof. Jiwen Lu of the Department of Automation. During undergraduate, I visited the GRASP Lab at University of Pennsylvania and worked with Prof. Jianbo Shi. My research aims to build multimodal intelligence that can perceive, reason about, and simulate the dynamic visual world we live in. I am particularly interested in complex video understanding, perception-centric reasoning, and training large multimodal models whose “thinking” is grounded in what they see and remember over time. Email / CV / Google Scholar / Github / Twitter |

|
|
|
* indicates equal contribution |

|
Benlin Liu, Arka Sadhu, Hyo Jin Kim, Kejie Li, Yifan Wang, Yuning Chai, Ranjay Krishna, Yuliang Li Under review |

|
Shaoxuan Li, Zhixuan Zhao, Hanze Deng, Zirun Ma, Shulin Tian, Zuyan Liu, Yushi Hu, Haoning Wu, Yuhao Dong*, Benlin Liu*, Ziwei Liu†, Ranjay Krishna† Under review * Project co-lead † Equal advising [Paper] |
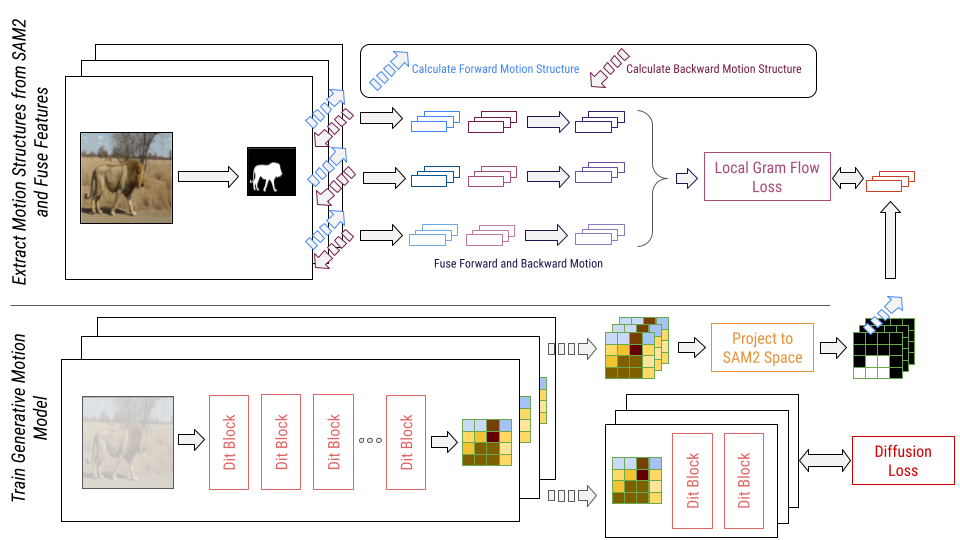
|
Yang Fei, George Stoica, Jingyuan Liu, Qifeng Chen, Ranjay Krishna, Xiaojuan Wang, Benlin Liu Under review [Paper] |
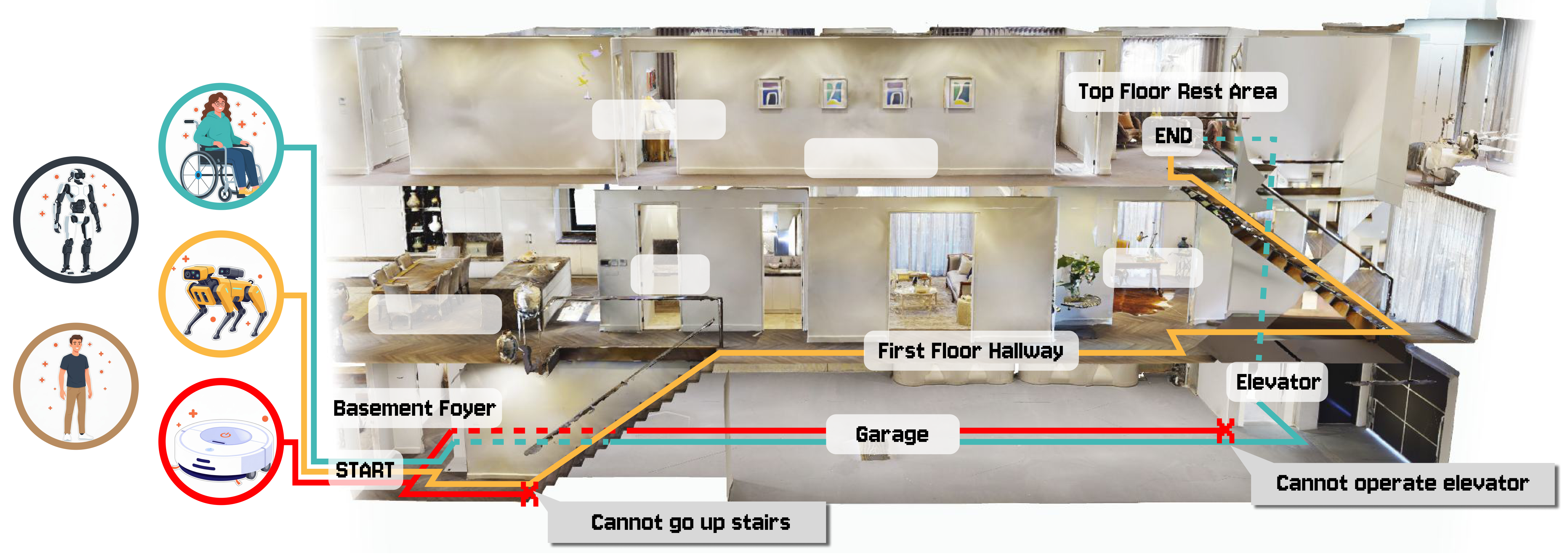
|
Xia Su, Ruiqi Chen, Benlin Liu, Jingwei Ma, Zonglin Di, Ranjay Krishna, Jon E. Froehlich Under review [Paper] |

|
Mingyang Fu, Yuyang Peng, Dongping Chen, Zetong Zhou, Benlin Liu, Yao Wan, Zhou Zhao, Philip S. Yu, Ranjay Krishna Advances in Neural Information Processing Systems (NeurIPS), 2025 [Paper] |
|
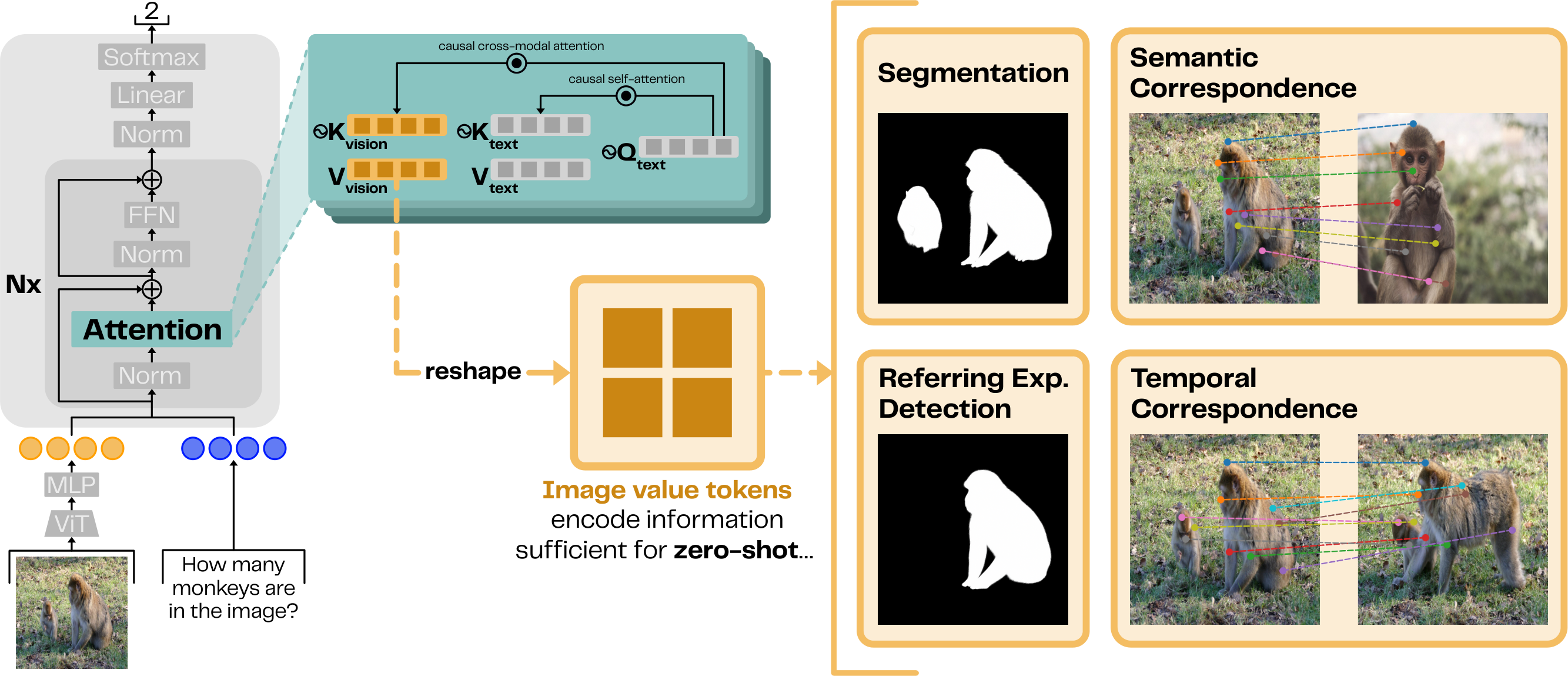
Benlin Liu, Amita Kamath, Madeleine Grunde-McLaughlin, Winson Han, Ranjay Krishna Conference on Language Modeling (COLM), 2025 [Paper] |
|
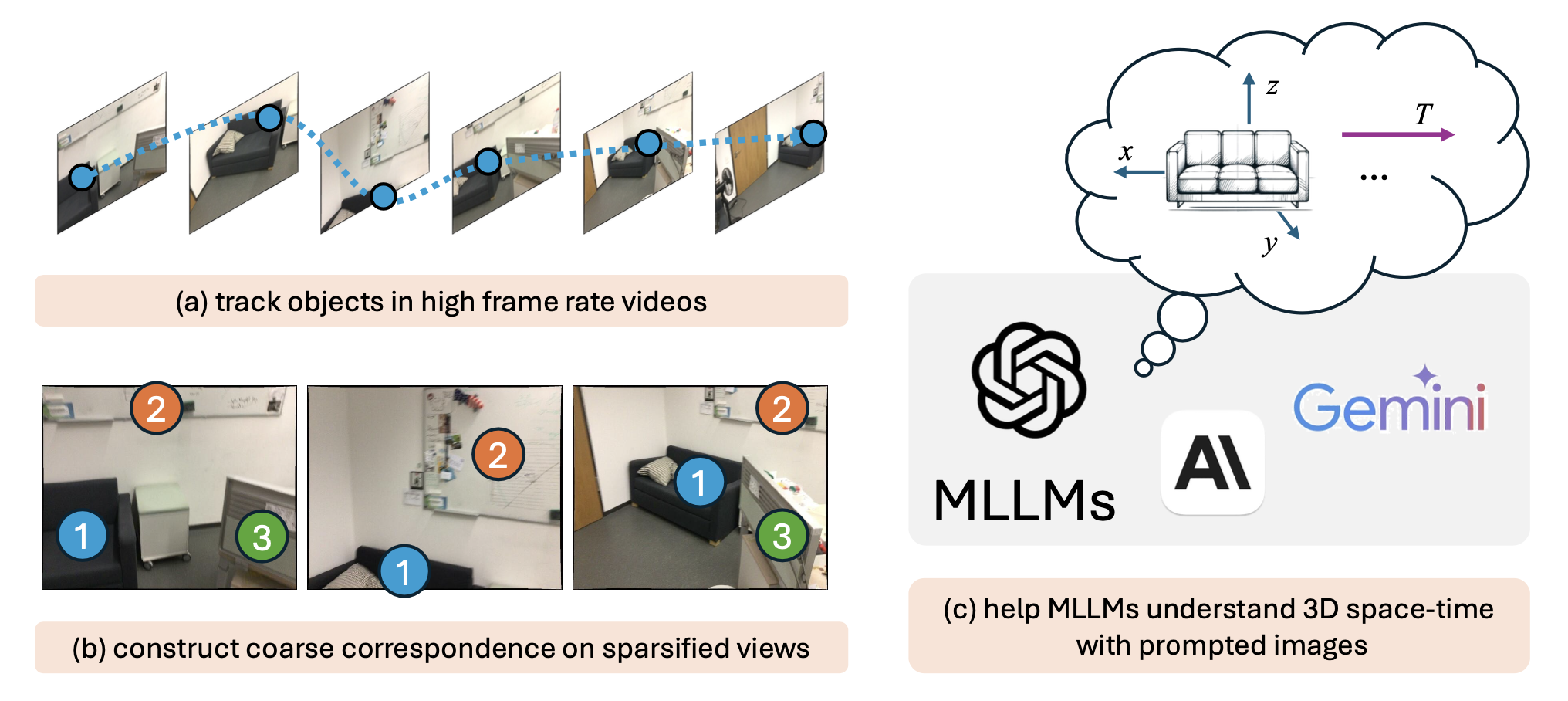
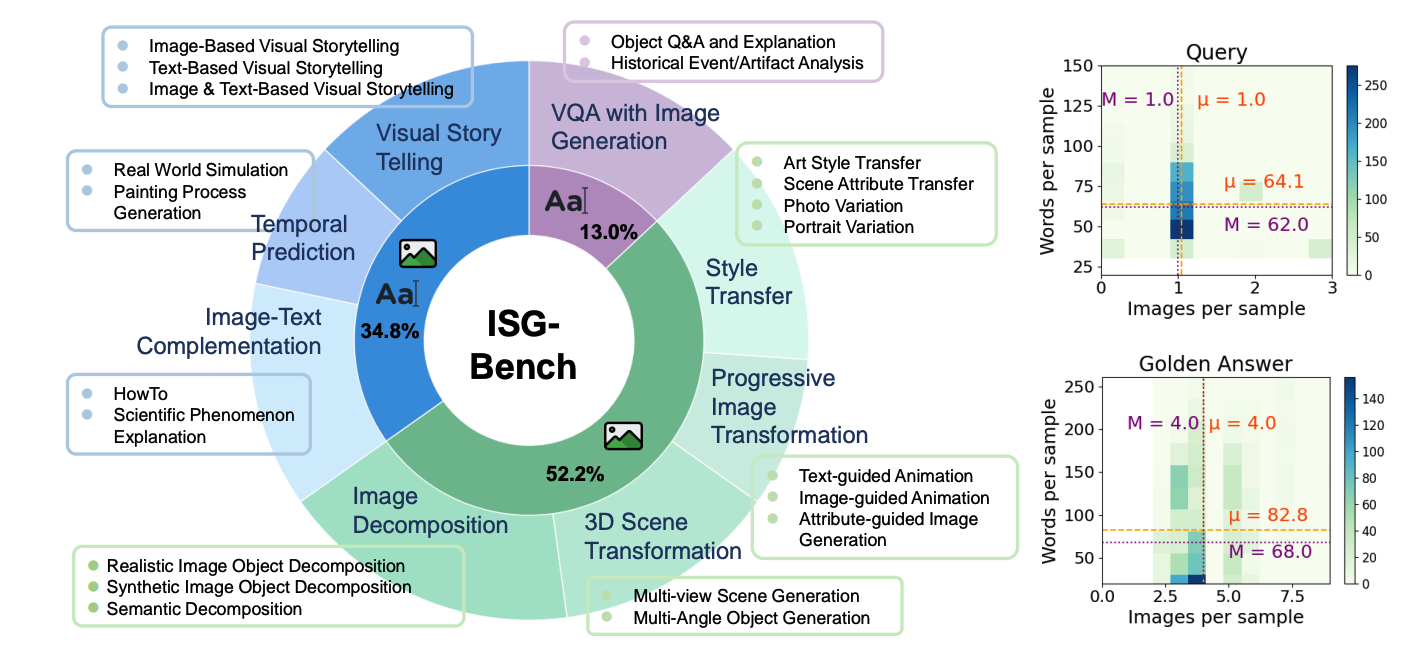
Benlin Liu, Yuhao Dong, Yiqin Wang, Zixian Ma, Yansong Tang, Luming Tang, Yongming Rao, Wei-Chiu Ma, Ranjay Krishna Conference on Computer Vision and Pattern Recognition (CVPR), 2025 [Paper][Project Page] |
|
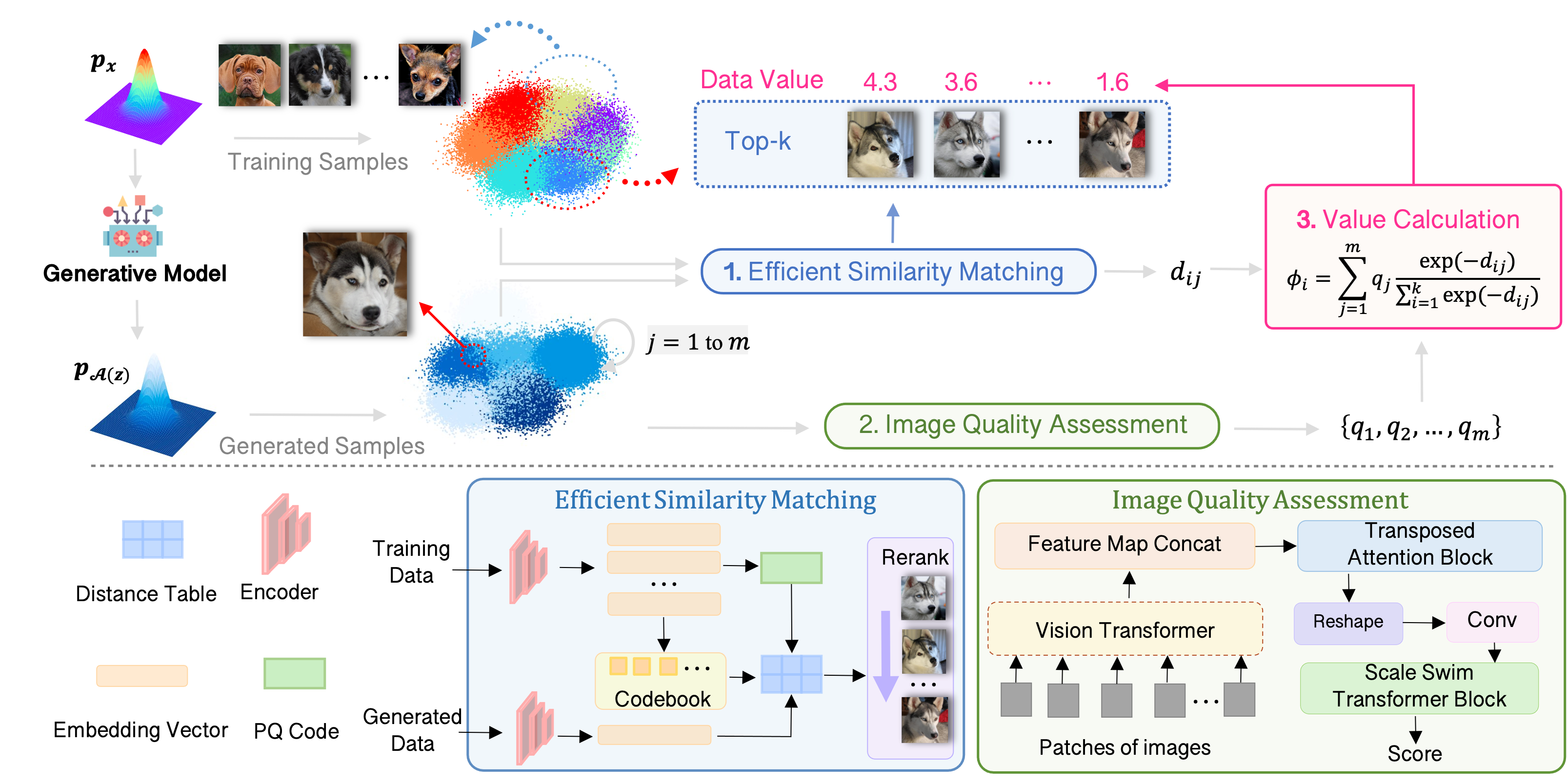
Dongping Chen, Ruoxi Chen, Shu Pu, Zhaoyi Liu, Yanru Wu, Caixi Chen, Benlin Liu, Yue Huang, Yao Wan, Pan Zhou, Ranjay Krishna International Conference on Learning Representations (ICLR), 2025 [Paper][Project Page] |
|
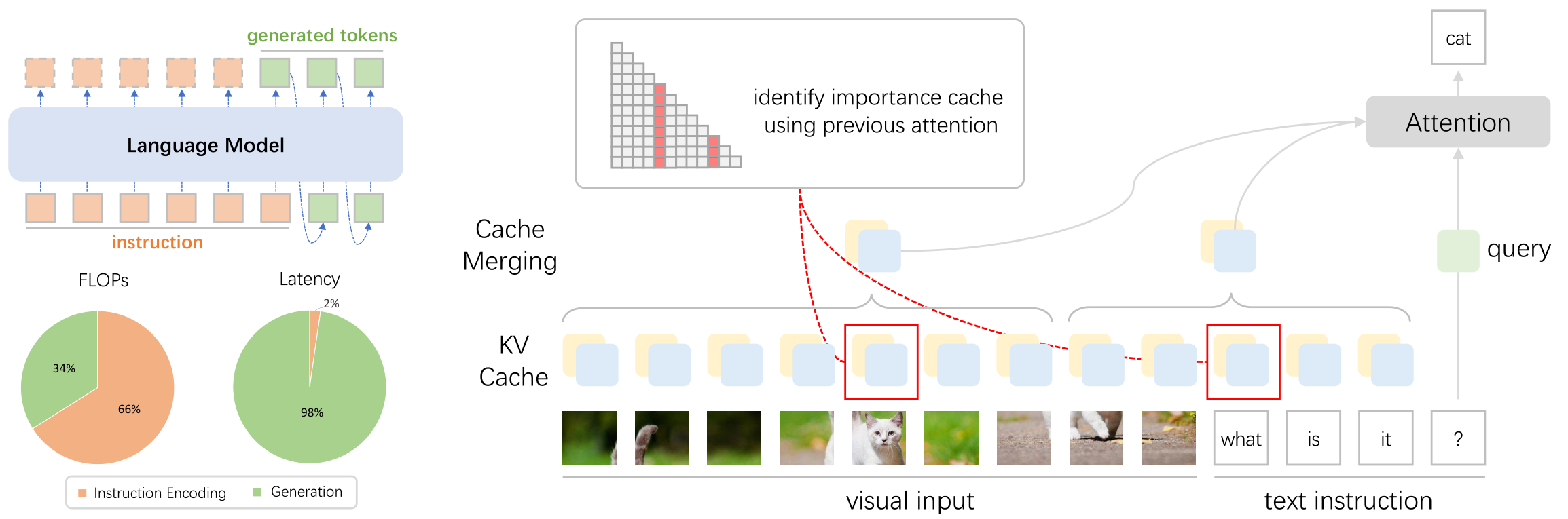
Jiaxi Yang, Wenlong Deng, Benlin Liu, Yangsibo Huang, James Zou, Xiaoxiao L International Conference on Learning Representations (ICLR), 2025 [Paper] |
|
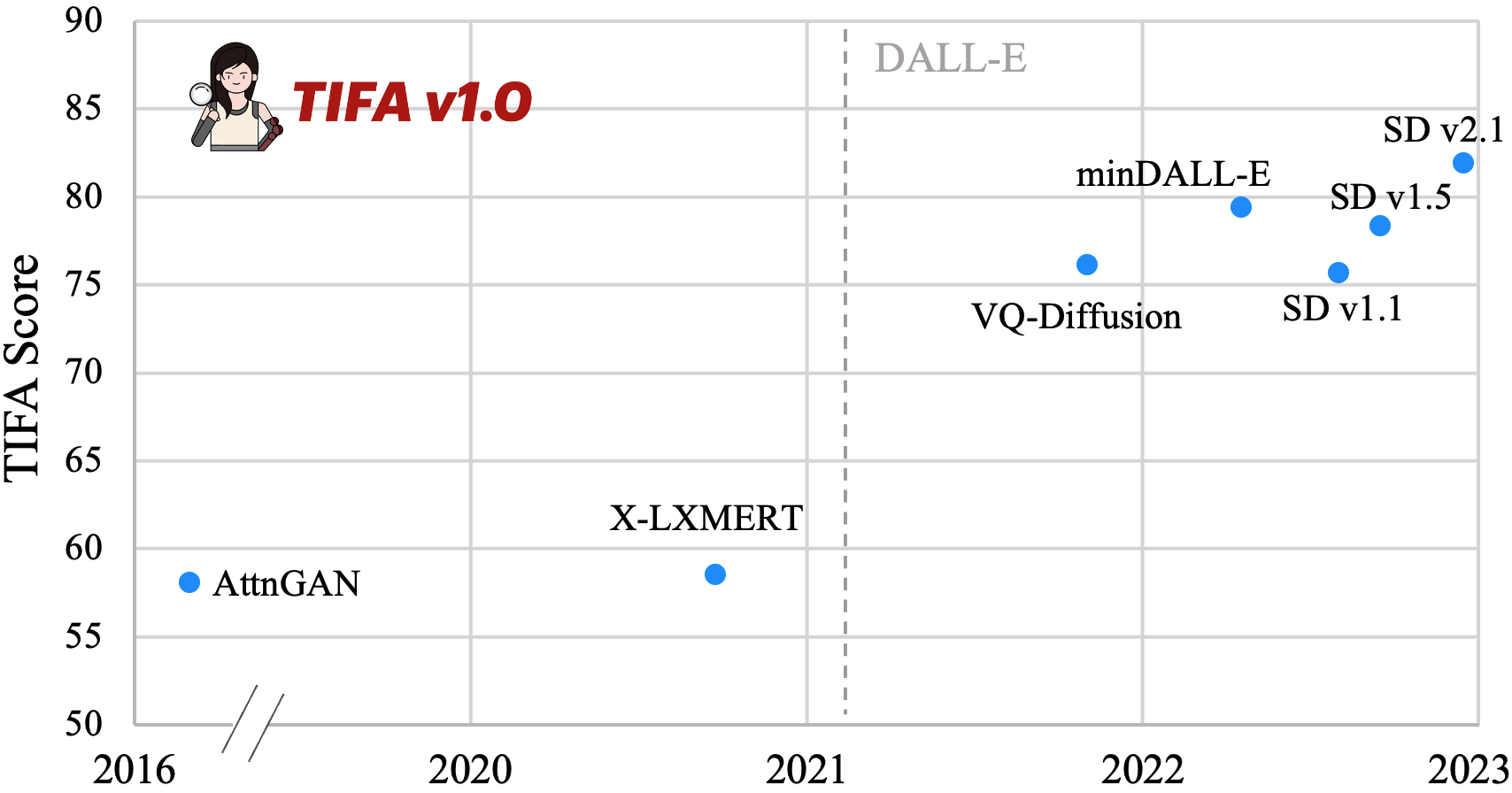
Zuyan Liu, Benlin Liu, Jiahui Wang, Yuhao Dong, Guangyi Chen, Yongming Rao, Ranjay Krishna, Jiwen Lu European Conference on Computer Vision (ECCV), 2024 [Paper] |
|
Yushi Hu, Benlin Liu, Jungo Kasai, Yizhong Wang, Mari Ostendorf, Ranjay Krishna, Noah A. Smith IEEE/CVF International Conference on Computer Vision (ICCV), 2023 [Paper][Project Page][Code] |
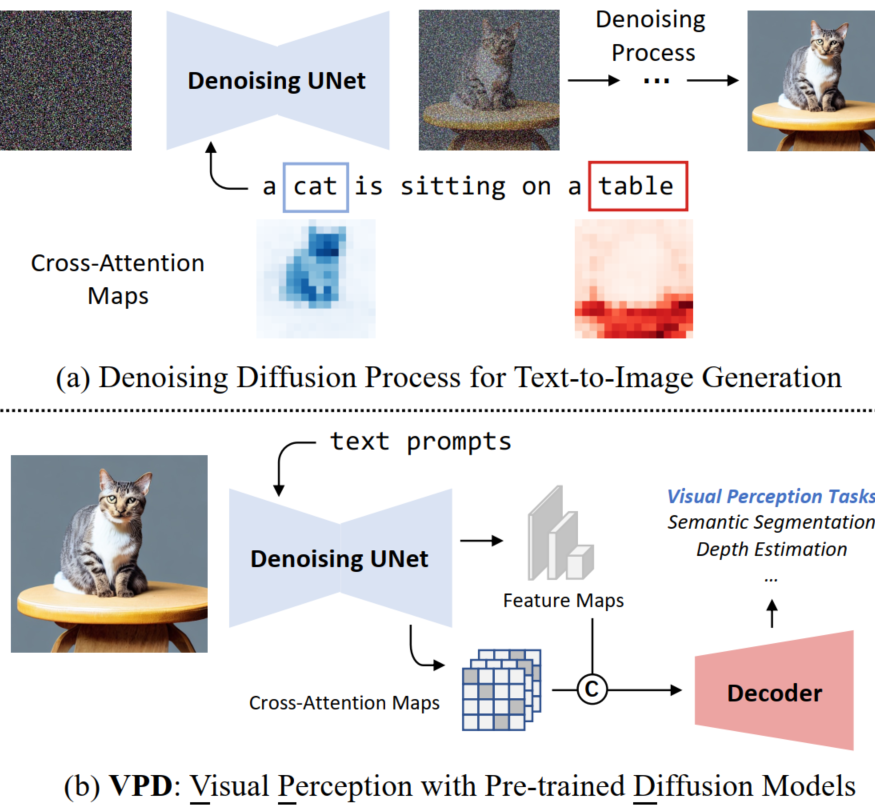
|
Wenliang Zhao*, Yongming Rao*, Zuyan Liu*, Benlin Liu, Jie Zhou, Jiwen Lu IEEE/CVF International Conference on Computer Vision (ICCV), 2023 [Paper][Project Page][Code] |

|
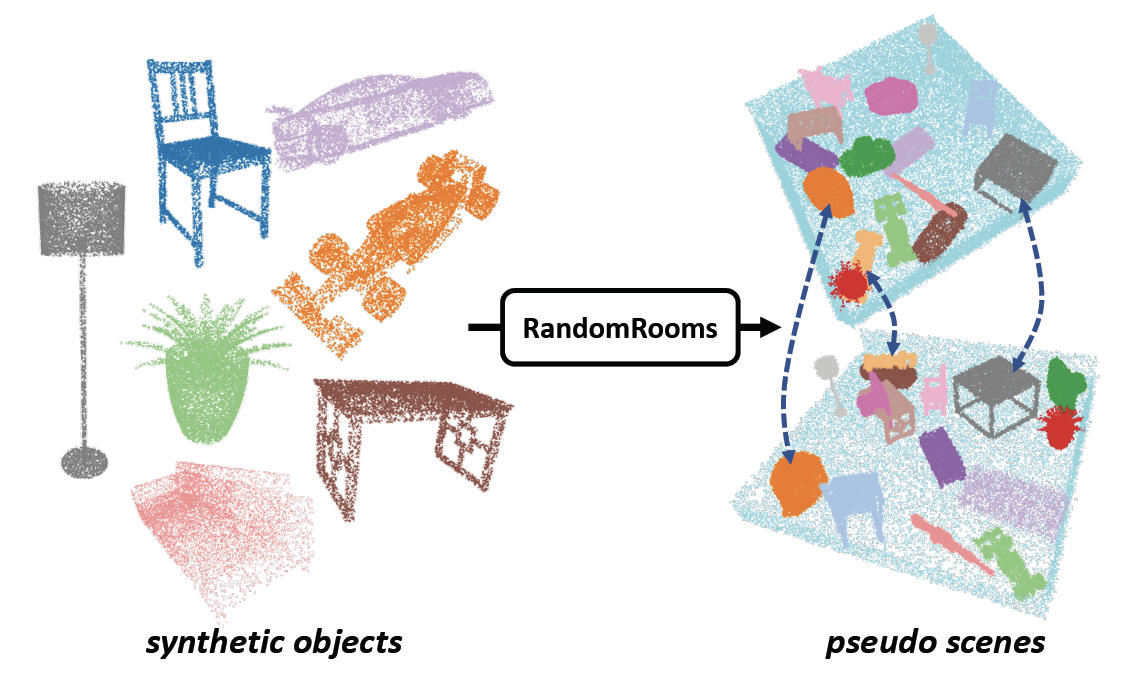
Yongming Rao, Wenliang Zhao, Benlin Liu, Jiwen Lu, Jie Zhou, Cho-Jui Hsieh Thirty-fifth Conference on Neural Information Processing Systems (NeurIPS), 2021 [Paper][Project Page][Code][Video] |
|
Benlin Liu*, Yongming Rao*, Yi Wei, Jiwen Lu, Cho-Jui Hsieh, Jie Zhou IEEE/CVF International Conference on Computer Vision (ICCV), 2021 [Paper] |
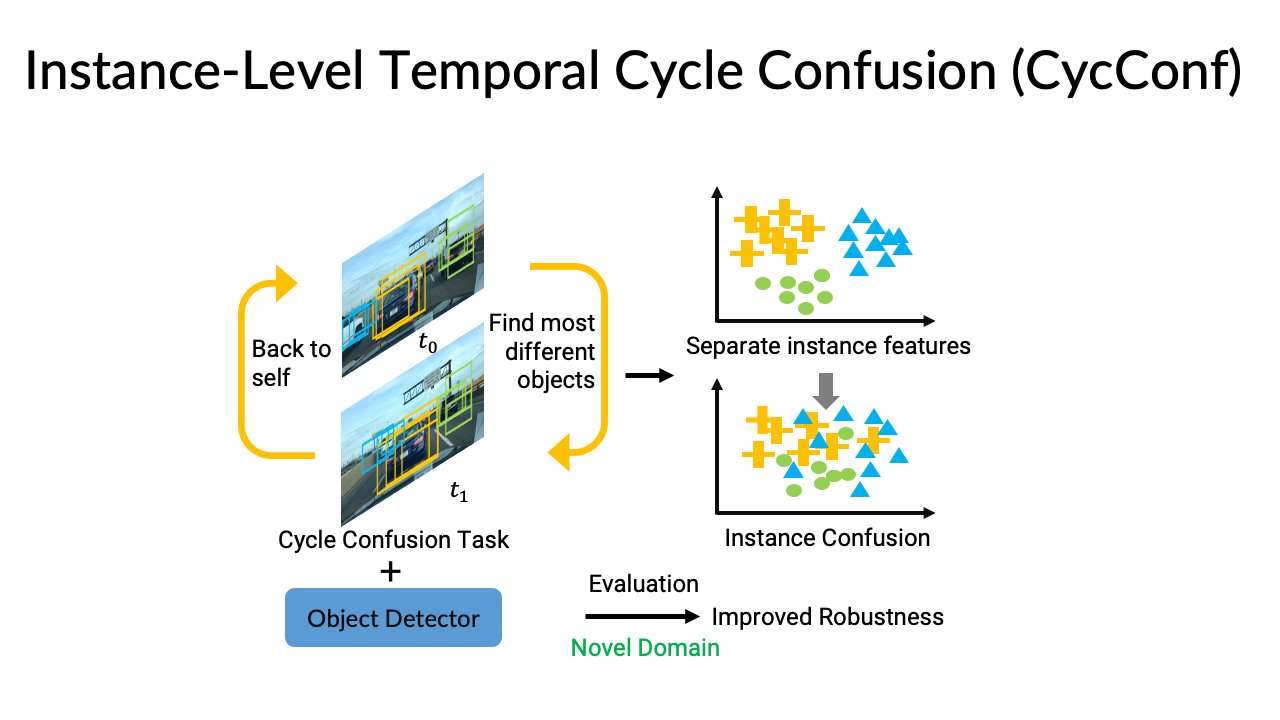
|
Xin Wang, Benlin Liu*, Thomas E. Huang*, Fisher Yu, Xiaolong Wang, Joseph E. Gonzalez, Trevor Darrell IEEE/CVF International Conference on Computer Vision (ICCV), 2021 [Paper][Project Page] |
|
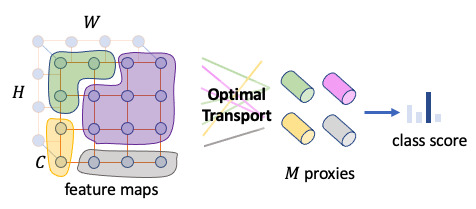
Benlin Liu*, Yongming Rao*, Jiwen Lu, Jie Zhou, Cho-Jui Hsieh 35th AAAI Conference on Artificial Intelligence (AAAI), 2021 [Paper] |
|
Benlin Liu, Yongming Rao, Jiwen Lu, Jie Zhou, Cho-Jui Hsieh 16th European Conference on Computer Vision (ECCV), 2020 [Paper] |
|
|
|
|